
2025 Major Release: Tencent Hunyuan Image 3.0 Complete Guide - In-Depth Analysis of the World's Largest Open-Source Text-to-Image Model
🎯 Key Points (TL;DR)
- Historic Breakthrough: Tencent has open-sourced the world's largest text-to-image model with 80B total parameters and 13B activated parameters during inference
- Technical Innovation: Hunyuan Image 3.0 adopts MoE architecture combined with Transfusion method, unifying multimodal understanding and generation capabilities
- Commercial-Grade Results: Hunyuan Image 3.0 image generation quality rivals industry-leading closed-source models, supporting precise Chinese and English rendering and ultra-long text understanding
- Fully Open Source: Hunyuan Image 3.0 provides complete source code, model weights, and commercial license for free use by individuals and enterprises
- Powerful Features: Hunyuan Image 3.0 supports world knowledge reasoning, thousand-character complex semantic understanding, and precise text generation
Table of Contents
- What is Hunyuan Image 3.0
- Core Technical Features Analysis
- Model Architecture and Innovation
- Installation and Deployment Guide
- Detailed Usage Instructions
- Effect Showcase and Case Studies
- Performance Evaluation Comparison
- Frequently Asked Questions
What is Hunyuan Image 3.0 {#what-is-hunyuan}
Hunyuan Image 3.0 is a revolutionary text-to-image model officially open-sourced by Tencent on September 28, 2025. This is the world's first open-source commercial-grade native multimodal image generation model and currently the largest open-source image generation model by parameter count.
Key Numbers
| Metric | Value | Description |
|---|---|---|
| Total Parameters | 80B | Hunyuan Image 3.0 is the world's largest open-source text-to-image model |
| Active Parameters | 13B | Hunyuan Image 3.0 parameters actually used during inference |
| Number of Experts | 64 | Hunyuan Image 3.0 expert modules in MoE architecture |
| Training Data | 5B image-text pairs + 6T tokens | Hunyuan Image 3.0 massive multimodal training data |
| Model Size | 160GB | Hunyuan Image 3.0 complete model weight file size |
💡 Technical Breakthrough
Unlike traditional DiT architectures, Hunyuan Image 3.0 adopts a unified autoregressive framework that achieves deep fusion of text and image modalities, which is key to the model's world knowledge reasoning capabilities.
Core Technical Features Analysis {#core-features}
1. World Knowledge Reasoning Capability
The biggest highlight of Hunyuan Image 3.0 is its world knowledge reasoning capability, meaning Hunyuan Image 3.0 can not only understand user descriptions but also combine common sense and professional knowledge to generate more accurate and richer images.
Typical Application Scenarios:
- Educational illustrations: Hunyuan Image 3.0 can generate nine-grid sketch tutorials, algorithm flow visualizations
- Science popularization diagrams: Hunyuan Image 3.0 can explain physical principles, historical events, biological processes
- Creative design: Hunyuan Image 3.0 can create visual works based on literary works and poetry
2. Ultra-Long Text Understanding
Hunyuan Image 3.0 supports thousand-character level complex semantic understanding, which is extremely rare among similar open-source models.
Hunyuan Image 3.0 supported text length: 1000+ characters
Hunyuan Image 3.0 language support: Chinese, English
Hunyuan Image 3.0 semantic understanding: Complex scene descriptions, multi-level detail requirements
3. Precise Text Rendering
Hunyuan Image 3.0 excels at generating text within images, supporting:
- Hunyuan Image 3.0 title text in poster designs
- Hunyuan Image 3.0 annotation text in infographics
- Hunyuan Image 3.0 brand logos and identifiers
- Hunyuan Image 3.0 multilingual text mixing
4. Diverse Artistic Styles
Hunyuan Image 3.0 model training covers rich artistic styles:
| Style Type | Hunyuan Image 3.0 Specific Performance | Applicable Scenarios |
|---|---|---|
| Photographic Realism | Hunyuan Image 3.0 film texture, professional lighting | Portrait photography, product shooting |
| Illustration Design | Hunyuan Image 3.0 flat design, hand-drawn style | Brand design, children's books |
| Artistic Creation | Hunyuan Image 3.0 oil painting, watercolor, sketching | Art creation, educational display |
| 3D Rendering | Hunyuan Image 3.0 material expression, lighting effects | Product visualization, architectural design |
Model Architecture and Innovation {#architecture}
MoE + Transfusion Architecture
The core innovation of Hunyuan Image 3.0 lies in combining Mixture of Experts (MoE) with the Transfusion method:
📊 Mermaid Diagram
Training Paradigm Innovation
Hunyuan Image 3.0 adopts a progressive training strategy:
- Pre-training Phase: Hunyuan Image 3.0 low resolution→High resolution, Low quality→High quality
- Instruction Tuning: Hunyuan Image 3.0 construct chain-of-thought image generation data to stimulate reasoning capabilities
- Supervised Fine-tuning: Hunyuan Image 3.0 use high-quality, high-aesthetic data
- Reinforcement Learning: Hunyuan Image 3.0 combine DPO and GRPO algorithms to improve aesthetic effects
⚠️ Technical Requirements
Due to Hunyuan Image 3.0 large model size, recommended configuration:
- GPU Memory: ≥3×80GB (recommended 4×80GB) for Hunyuan Image 3.0
- Storage Space: 170GB for Hunyuan Image 3.0
- System Requirements: Linux + CUDA 12.8 for Hunyuan Image 3.0
Installation and Deployment Guide {#installation}
Environment Setup
# 1. Install PyTorch (CUDA 12.8 version)
pip install torch==2.7.1 torchvision==0.22.1 torchaudio==2.7.1 --index-url https://download.pytorch.org/whl/cu128
# 2. Install other dependencies
pip install -r requirements.txt
# 3. Performance optimization components (optional, 3x inference speed boost)
pip install flash-attn==2.8.3 --no-build-isolation
pip install flashinfer-python
Model Download
# Download model from HuggingFace
hf download tencent/HunyuanImage-3.0 --local-dir ./HunyuanImage-3
Quick Start
Method 1: Using Transformers Library
from transformers import AutoModelForCausalLM
# Load model
model_id = "./HunyuanImage-3"
kwargs = dict(
attn_implementation="sdpa",
trust_remote_code=True,
torch_dtype="auto",
device_map="auto",
moe_impl="eager",
)
model = AutoModelForCausalLM.from_pretrained(model_id, **kwargs)
model.load_tokenizer(model_id)
# Generate image
prompt = "A brown and white dog running on the grass"
image = model.generate_image(prompt=prompt, stream=True)
image.save("image.png")
Method 2: Command Line Usage
python3 run_image_gen.py --model-id ./HunyuanImage-3 --prompt "A brown and white dog running on the grass"
Detailed Usage Instructions {#usage}
Prompt Writing Tips
For optimal results, it's recommended to structure prompts as follows:
Subject and Scene + Image Quality and Style + Composition and Perspective + Lighting and Atmosphere + Technical Parameters
Example Prompt:
Cinematic shot, beside a vintage earthy yellow car, a man in a dark blue shirt leans against the car with a cigarette in his mouth, bright sunlight, warm yellow and deep cyan tones, delicate lighting and shadows, refined colors
Model Version Selection
| Model Version | Hunyuan Image 3.0 Features | Applicable Scenarios |
|---|---|---|
| HunyuanImage-3.0 | Hunyuan Image 3.0 base version, doesn't automatically rewrite prompts | Professional users, precise control |
| HunyuanImage-3.0-Instruct | Hunyuan Image 3.0 instruction version, supports prompt rewriting and reasoning | General users, intelligent optimization |
Advanced Parameter Settings
# Complete parameter example
python3 run_image_gen.py \
--model-id ./HunyuanImage-3 \
--prompt "Your prompt" \
--seed 42 \
--diff-infer-steps 50 \
--image-size 1280x768 \
--attn-impl flash_attention_2 \
--moe-impl flashinfer \
--save output.png
Effect Showcase and Case Studies {#showcase}
World Knowledge Reasoning Cases
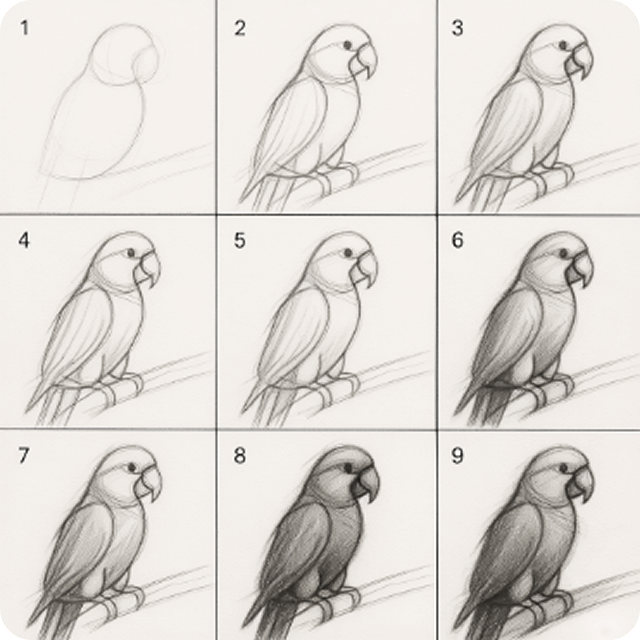
Prompt: "Generate a nine-grid tutorial showing how to sketch a parrot"
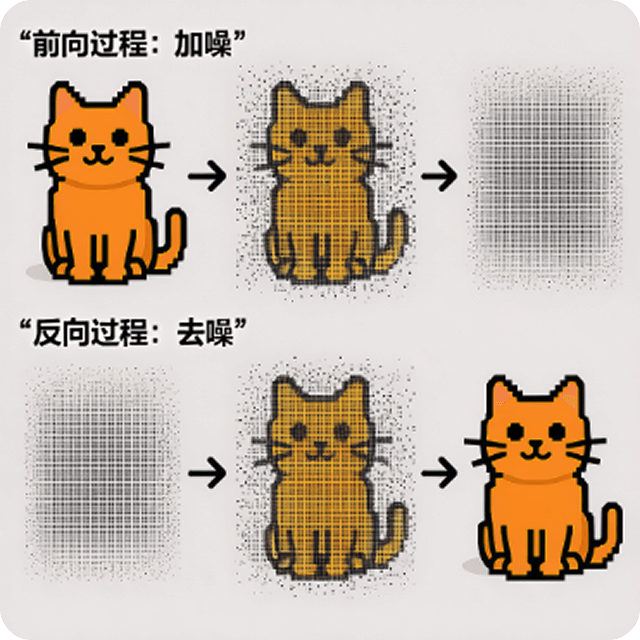
Prompt: "Create an illustration with simple text introduction explaining the principles of diffusion generative models"
Ultimate Aesthetic Cases
Prompt: "This is a magazine-style poster with extreme visual impact, shrouded in a dark, ghostly mysterious atmosphere, with a minimalist high-end pure red background..."

Prompt: "Film photography, motion blur, a handsome Chinese youth running quickly by the lake, smiling, fluffy hair, white shirt..."

Precise Text Generation Cases
Prompt: "Master-level typography + maximalism, incorporating halftone textures, noise grain and warm analogous color gradients..."

Prompt: "3D rendering style promotional poster, mainly green and white color scheme, full of youthful vitality..."

Performance Evaluation Comparison {#evaluation}
SSAE Machine Evaluation
SSAE (Structured Semantic Alignment Evaluation) is an intelligent evaluation metric based on multimodal large language models, assessing 3,500 key points across 12 categories for Hunyuan Image 3.0.
| Model | Mean Image Accuracy | Global Accuracy |
|---|---|---|
| HunyuanImage-3.0 | 85.2% | 87.4% |
| DALL-E 3 | 82.1% | 84.6% |
| Midjourney v6 | 81.8% | 83.9% |
| Stable Diffusion 3 | 78.5% | 80.2% |
GSB Human Evaluation
Using Good/Same/Bad evaluation method, 100+ professional evaluators assessed Hunyuan Image 3.0 images generated from 1,000 prompts:
| Hunyuan Image 3.0 Comparison Model | Good | Same | Bad |
|---|---|---|---|
| Hunyuan Image 3.0 vs DALL-E 3 | 52% | 31% | 17% |
| Hunyuan Image 3.0 vs Midjourney v6 | 48% | 35% | 17% |
| Hunyuan Image 3.0 vs Flux.1 | 61% | 28% | 11% |
✅ Evaluation Conclusion
Hunyuan Image 3.0 performs excellently in multiple evaluations, particularly showing significant advantages in text rendering, complex scene understanding, and artistic style expression.
🤔 Frequently Asked Questions {#faq}
Q: What advantages does Hunyuan Image 3.0 have compared to other open-source models?
A: Hunyuan Image 3.0 main advantages include:
- Largest Scale: Hunyuan Image 3.0 80B parameters, far exceeding other open-source models
- World Knowledge Reasoning: Hunyuan Image 3.0 can generate images based on common sense and professional knowledge
- Ultra-Long Text Understanding: Hunyuan Image 3.0 supports 1000+ character complex descriptions
- Commercial-Grade Quality: Hunyuan Image 3.0 effects rival closed-source models
- Fully Open Source: Hunyuan Image 3.0 provides complete source code and commercial license
Q: What hardware configuration is needed to run Hunyuan Image 3.0?
A: Hunyuan Image 3.0 recommended configuration:
- GPU: 3×80GB or 4×80GB VRAM (such as A100, H100) for Hunyuan Image 3.0
- Storage: 170GB available space for Hunyuan Image 3.0
- Memory: 64GB+ system memory for Hunyuan Image 3.0
- System: Linux + CUDA 12.8 for Hunyuan Image 3.0
Q: Does it support commercial use?
A: Yes, Hunyuan Image 3.0 uses an open-source license that allows free use by individuals and enterprises, including commercial purposes.
Q: How to optimize Hunyuan Image 3.0 inference speed?
A: Hunyuan Image 3.0 recommended to install performance optimization components:
pip install flash-attn==2.8.3 --no-build-isolation
pip install flashinfer-python
This can improve Hunyuan Image 3.0 inference speed by up to 3x.
Q: What image resolutions does Hunyuan Image 3.0 support?
A: Hunyuan Image 3.0 supports multiple resolutions:
- Auto Mode: Hunyuan Image 3.0 automatically predicts the most suitable resolution based on prompts
- Specified Mode: Hunyuan Image 3.0 supports common ratios like 16:9, 4:3, etc.
- Custom: Hunyuan Image 3.0 can specify exact pixel dimensions like 1280x768
Q: How to achieve better Hunyuan Image 3.0 generation results?
A: Hunyuan Image 3.0 recommendations:
- Detailed Descriptions: Provide rich scene and detail descriptions for Hunyuan Image 3.0
- Structured Prompts: Organize in order of subject→style→composition→lighting for Hunyuan Image 3.0
- Use Instruct Version: Hunyuan Image 3.0 supports automatic prompt optimization
- Reference Official Cases: Learn from excellent Hunyuan Image 3.0 prompt writing
Summary and Outlook
The release of Tencent Hunyuan Image 3.0 marks a major breakthrough in the open-source AI image generation field. As the world's largest open-source text-to-image model, it not only achieves multiple technical innovations but more importantly provides a powerful foundational tool for the entire AI community.
Core Value
- Technology Democratization: Hunyuan Image 3.0 enables more developers and researchers to use top-tier image generation technology
- Business-Friendly: Hunyuan Image 3.0 fully open-source commercial license lowers enterprise application barriers
- Innovation Driver: Hunyuan Image 3.0 MoE+Transfusion architecture points the way for future multimodal model development
- Ecosystem Building: Hunyuan Image 3.0 rich documentation and community support promote technology adoption
Next Steps Recommendations
For Developers:
- Download Hunyuan Image 3.0 for technical validation and integration testing
- Participate in Hunyuan Image 3.0 community discussions and contribute optimization suggestions
- Develop innovative applications based on Hunyuan Image 3.0
For Enterprises:
- Evaluate Hunyuan Image 3.0 application potential in specific business scenarios
- Consider integrating Hunyuan Image 3.0 into existing products and services
- Develop technology development strategies based on Hunyuan Image 3.0 open-source AI
For Researchers:
- Deeply study Hunyuan Image 3.0 technical details of MoE+Transfusion architecture
- Explore new directions in Hunyuan Image 3.0 multimodal unified modeling
- Advance academic research in Hunyuan Image 3.0 related fields
🚀 Future Outlook
According to the official roadmap, Hunyuan Image 3.0 will subsequently launch image-to-image, multi-turn interaction, distilled versions and other features, further expanding application scenarios and lowering usage barriers.
Related Resources:
- Official Website: https://hunyuan.tencent.com/image
- GitHub Repository: https://github.com/Tencent-Hunyuan/HunyuanImage-3.0
- HuggingFace Model: https://huggingface.co/tencent/HunyuanImage-3.0
- Technical Report: HunyuanImage 3.0 Technical Report
- Hunyuan Image 3.0 Complete Guide